MIT6.824 —— MapReduce
这篇文章是我实现6.824的lab1-MapReduce的一些记录。
MapReduce
MapReduce是非常成功的分布式系统的编程模型,用于超大数据量的计算处理。在MapReduce 模型设计下,系统支持水平扩展,能够将计算任务分配到大规模机器集群上并行执行。
通常分为Map和Reduce任务,Map任务负责执行业务逻辑处理一个key、value的输入,输出处理后的中间数据集合,Reduce任务基于输出的中间数据将Map任务的结果进行归并。
分布式系统设计的最理想的是构建将分布式特性隐藏在系统中的架构,使得应用层角度来看整个系统仍然是非分布式的, 应用程序设计人员和分布式运算的使用者,只需要实现业务逻辑的Map函数和Reduce函数,而不需要关注分布式系统的具体实现细节。
更多内容阅读MapReduce paper。
Lab实现
(一)架构与Master实现
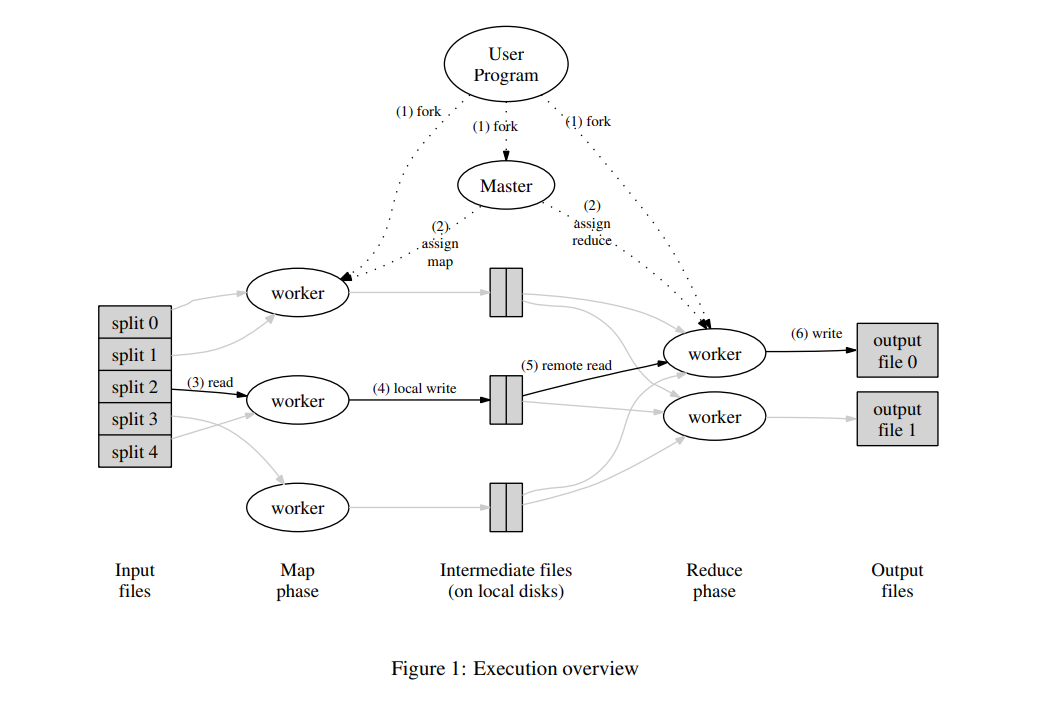 根据MapReduce paper中的架构示意图,集群中节点分为2类:
根据MapReduce paper中的架构示意图,集群中节点分为2类:
- master
集群中唯一,作为调度者,负责任务的分配 - worker
集群中除master之外都是worker,是Map、Reduce任务的执行者
master负责任务的调度,维护任务队列,这里任务队列指的是调度者用来管理任务状态的数据结构,可以有多种实现,常见结构为队列或数组。
worker和master之间通信通过rpc,worker的rpc请求对应到master进程上的一个Goroutine,所以任务队列是一个共享变量,这种并发模式非常类似线程池的实现。
// 常见的实现方式:
worker1 worker2 worker3
┌───┐ ┌───┐ ┌───┐
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
└─┬─┘ └─┬─┘ └─┬─┘
│ │ │
│ get&set work│
│ │ │
▼ ▼ ▼
┌─────────────────────────────┐
│ work queue │
└─────────────────────────────┘
▲
│
get&set work
│
┌─┴─┐
│ │
│ │
│ │
└───┘
master
如上示意图,可以看出这种实现的并发能力并不高,任务队列作为共享变量被并发的多读多写,需对其加锁才能确保安全进行,并且锁粒度较大。
// 我的实现方式:
┌─────────────────────────────┐
│ work queue │
└─────────────────────────────┘
▲
│
│
get&set work
│
│
┌────┴────┐
│ │
│ │
│ │
├─────────┤ ┌─────────┐
│ │◄─────────┤ │ worker1
│ │ └─────────┘
│ channel │
│ │ ┌─────────┐
│ │◄─────────┤ │ worker2
└─────────┘ └─────────┘
master
所有worker goroutine对任务队列的修改都由master goroutine进行转发,那么任务队列就只有一个goroutine读写,这样就避免了对任务队列的加锁操作。
同时master作为调度者也更加方便的制定调度策略,比如检测任务超时之类。
Master结构体
// Coordinator is Master
type Coordinator struct {
// ...
// work queue
tasks []Task
// chan
registerCh chan RegisterMsg
taskReleaseCh chan TaskReleaseMsg
taskResultCh chan TaskResultReq
// ...
}
上面就是我实现的master结构体,其中维护着任务队列——tasks,所有worker的rpc请求都会对应到各自协议处理的channel中去,然后由master进程中的一个特定goroutine 统一处理,做到tasks只由这一个goroutine读写。
func (c *Coordinator) schedule() {
c.initMapPhase()
for {
select {
case msg := <-c.registerCh:
// ...
msg.ok <- struct{}{}
case msg := <-c.taskReleaseCh:
// ...
msg.ok <- struct{}{}
case msg := <-c.taskResultCh:
// ...
}
}
}
(二)流程设计
流程上主要是worker如何从master处获取任务,在任务完成时如何上传任务结果,任务超时master又如何处理,关键在于如何定义往来协议。
协议
// return task config
type RegisterReq struct {
}
type RegisterRes struct {
NMap int
NReduce int
Ok bool
}
// task receive
type TaskReceiveReq struct {
}
type TaskReceiveRes struct {
JobType JobType
JobId int
FileName string
}
// task result
type TaskResultReq struct {
JobType JobType
JobId int
Result bool
}
type TaskResultRes struct {
}
比较简单,包括3对作用明确的协议——Register、TaskReceive、TaskResult,启动时worker发送Register到master,获取到任务的一些配置项,然后发送TaskReceive获取到任务,任务完成或出错时发送TaskResult到master上报处理结果。
可以看出我并未在master上维护worker的状态,在Register时也未分配id给worker,目的是实现一个无状态的worker,master只关注tasks中任务的状态,降低复杂度。
(三)注意点
Lab-mr 和 MapReduce paper中给出了很多实现的细节,比如节点失效的处理、中间文件的格式及命名规范等,建议仔细阅读。
Master/Worker 失效
- Master Failure
master是单点,master宕机会导致所有任务状态丢失,所以只能人工干预,重新开始任务,也可以设置任务状态的存盘(checkpoints),重新启动时读取存盘数据恢复;
- Worker Failure
首先是需要检测到worker的失效,由于worker是无状态,master没有维护对worker的心跳,所以只能通过任务执行的超时判定worker失效,当任务超时master会将任务状态由Doing转变为Idle,再将任务分配给其他worker。
worker也需要实现一些确保机制,保证异常退出的worker不会影响其他worker对这个task的执行。
- 幂等的map、reduce函数(不同的worker处理相同的输入获得相同的输出)
- 任务结果输出到临时文件的操作具有原子性,即只有成功执行的任务,输出的临时文件才会被后续处理过程读取到
Atomic Write File
需要确保map、reduce任务生成输出文件时的原子性,是为了防止文件写入过程中出现问题时异常文件不被其他程序发现。
具体方法就是先输出到临时文件,最后再用系统调用 OS.Rename 重命名临时文件实现原子性替换。
总结
MapReduce是一篇2004年的paper,其中提到系统的性能瓶颈受限于网络带宽,也提出了在master上基于文件位置信息分配最近的worker的优化。 可是随着基础设施的优化,网络带宽可能不再是系统的瓶颈,为了更快的速度新系统架构中可能会考虑更少的磁盘IO,更多的利用内存和网络。
虽然paper中有一些经验可能随着技术的进步已经不再适用,或者有更好的替代方案,但是它对分布式系统中部分问题的处理以及工程思想非常值得我们学习。
例如模型的设计中提到把分布式的复杂性隐藏在架构中,这不也是如今Service Mesh中Sidecar的思想?
优秀的的设计思想总是不谋而合!