分布式ID生成方案对比
概述
在各种业务场景中总会出现需求用id去标识一个玩家、一件物品或者一个订单,需确保这个id在整个系统中不重复,做到全局唯一。
特别是在分布式系统中如何去生成这样一个id?又有哪些考量指标?
评价指标
- 全局唯一
生成的id不重复,满足分布式系统要求
- 性能
生成、查重效率
- 第三方依赖
是否通过数据库(MySQL、Mongo ..)、配置中心(etcd、zk ..)等第三方系统确保生成;
- 可用性
是否依赖数据库的高可用或者是依赖于机器的时钟;
- 无序或者有序
是否趋势递增或单调递增,根据实际业务需求出发,并非有序就一定优于无序。
如果玩家id自增,就能通过id知道当前系统的用户量。
生成方式
不依赖第三方
- UUID (Universally Unique Identifier)
基于时间、计数器、硬件标识(通常为无线网卡的MAC地址)等数据计算生成,在Java、C#中都提供对于的接口。
优点:生成简单,本地生成,无网络消耗,具有唯一性。
缺点:1)长度较长、不易存储;
2)无序且不能携带有效信息;
3)信息不安全,基于MAC地址生成会泄漏MAC地址;
4)一些数据库如果较长的id作为数据库的主键可能会存在问题。
MySQL长字段作为主键索引,会造成以下几个问题:
- 主键索引占用空间大,一个页的数据量更少,相对查找的IO次数也更多;
- 比对消耗的时间也更长;
- innodb中辅助索引的叶节点记录的是主键值,所以也会增加辅助索引的空间占用;
- 无序节点的变动,会导致底层树的不平衡,降低索引性能。
- 雪花算法
twitter/snowflake, baidu/uid-generator, Meituan-Dianping/Leaf
基于时间戳、机器id加上自增值部分生成。
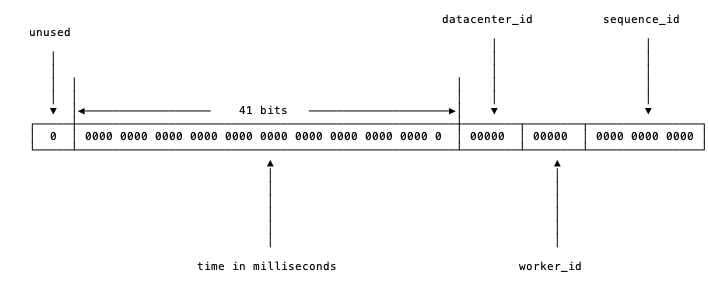
1)毫秒数在高位,自增序列在低位,id递增趋势;
2)不依赖第三方,性能较高;
3)根据业务分配bit位,灵活度较高。
System Clock Dependency:强依赖机器时钟,如果机器时钟回拨,会导致发号重复或服务不可用。
依赖第三方
- 数据库自增id
通过数据库自增id字段来生成uid,比如使用MySQL的auto_increment字段,又或者原子操作redis、mongo字段来实现。
实现简单,id单调递增,查询速度较快
数据库负责并发问题
1)存在网络延迟,每一次生成都需要执行一次数据库插入或更新操作;
2)瓶颈转移至数据库,存在单点风险;
3)依赖于数据库的并发量。
- 号段模式
是对数据库自增id方式的优化,通过一次访问数据库获得一个范围内id的分配权利,减少对数据库的访问。
优点:1)不频繁访问数据库;
2)id趋势递增。
1)不是单调递增;
2)获得号段后,节点挂掉会造成id的浪费。
一种数据库自增id到无序id的生成方案
需求:
如果有需求我们不想要UUID和snowflake这样的较长id,比如想生成[0, 999999]范围内的id,但是又要确保生成的id无序。
方案:
最简单的方式本地随机选取[0, 999999]范围内的一个id,然后去数据库判断是否已经被使用,明显这种方式在后期id大部分被使用时,可能出现随机好几次的id都已经被使用的情况。严重影响生成效率。
优化方案:
前面提到的数据库自增id字段的方式,就是能很好避免这种重复查重,每一次获取的id都是未使用的。
那么需求就变为如何通过自增字段分配到的有序id转化为乱序id。
假设:有序集合 A ([0, 999999]) 中的元素 m,通过算法 F() 映射到另一个集合 Q 的元素 c 上,满足如下关系:
$c = F(m) m\in A, c\in Q$
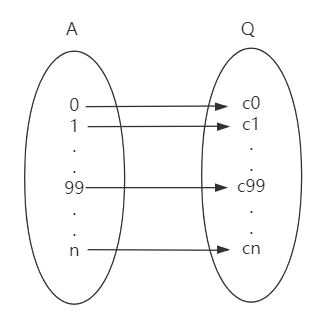
集合 A 和集合 Q 之间的映射满足上图关系,即算法 F() 为双射(Bijection)函数。
有这样的双射函数后就可以将分配到的有序id映射到乱序id,满足所有的需求。
问题就到了寻找一个合适的双射函数上,非对称加密的RSA算法就是一个非常符合要求的算法。
具体实现不再赘述,大家可以去看看RSA算法的具体实现,[0, 999999)范围有效的RSA,加密过程将数据库分配的id,映射到[0, 999999)中的一个乱序数字,解密过程通过乱序数字获得数据库分配的有序id。
图片来源(侵删):
图1 snowflake的比特位